
[Paper Review] QuestEval: Summarization Asks for Fact-based Evaluation (EMNLP 2021)
Published:
QA를 통해 요약 성능 테스트하기
Abstract
요약문을 평가하는 연구는 현재까지 어려움으로 남아있다. 가장 많이 사용하는 평가 방법인 ROUGE의 경우 사람의 평가와는 연관성이 낮다고 알려졌다. 이러한 문제를 해결하기 위해 최근에 question answering 모델들을 사용하여 요약문이 본문의 중요한 내용을 포함하고 있는 지 평가하고 있다. 하지만 아직 ROUGE보다 사람의 평가와 상관관계가 높은 평가 방법이 제안되지 않았다. 해당 논문에서는 기존의 평가 방법들과 다르게 정답 요약문 없이 요약문을 평가하는 방법인 QuestEval을 제안한다.
Introduction
Automatic 평가 방법의 신뢰성은 인공지능 분야에서 중요한 요소이다. 특히 natural language generation (NLG) 태스크를 평가하는 것은 어렵다. 기존의 연구들은 현재 많이 사용하는 평가 지표들이 사람의 평가와 상관 관계가 떨어진다고 주장한다. NLG 태스크 중에서도 요약 분야는 특히 어려운 분야이다. 하나의 본문의 가능한 정답 요약문은 여러 개인데, 그 중 정답 요약문이 하나로 설정했기 때문에 하나의 정답 요약문을 사용해서 평가를 하게 된다면 제대로 된 평가가 이루어지지 않는다. 또한 요약문의 경우 길이가 짧기 때문에 본문의 중요한 정보만을 내포해야 하는데, ROUGE와 같이 단순히 n-gram overlap을 계산하는 metric의 경우, 이러한 중요한 문장에 대해 평가를 할 수 없다. 또한 요약문의 중요한 요소 중 하나인 hallucination과 같은 factual consistency도 ROUGE로는 평가할 수 없다.
따라서 이러한 문제를 해결하기 위해 최근에는 question generation과 question answering을 활용한 평가 지표들을 사용하고 있다. 이러한 지표들은 요약문이 중요한 정보를 충분히 내포하고 있는지(relevance-recall), 잘못된 정보는 없는 지(consistency-precision)에 대해 평가할 수 있다. 해당 논문에서는 마찬가지로 QA를 활용하여 정답 요약문이 없는 환경에서 요약 모델을 평가하는 QuestEval 방법을 제안한다.
Method (A Question-Answering based Framework)
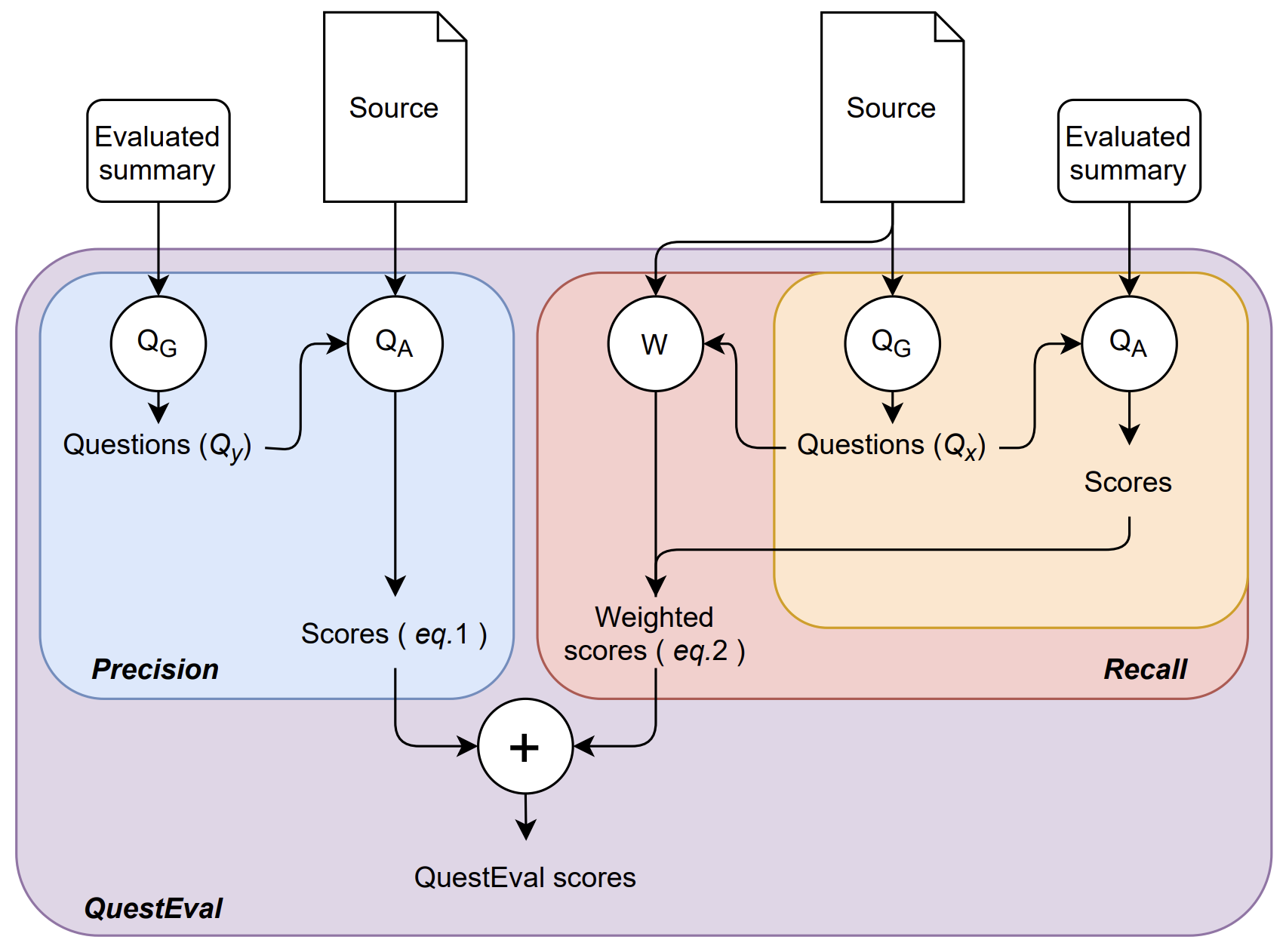
해당 논문에서는 요약 모델을 평가하기 위해 QuestEval 프레임워크를 제안한다. 해당 방법을 통해 reference-free 환경에서 요약문의 factual consistency와 relevance를 평가할 수 있다. QuestEval은 Question Generator (QG)와 Question Answering (QA)를 포함한다.
Question Answering
QA 컴포넌트로 T5 모델을 활용하여 입력으로 본문과 질문이 들어왔을 때, 정답을 추출한다. 만약 요약문에 정답이 없는 질문이 들어왔을 때는 unanswerable 토큰을 사용한다.
Question Generation
먼저 본문의 모든 named entity와 명사를 정답으로 추출하고. 추출된 정답을 토대로 beam search를 통해 질문을 생성한다. QG 컴포넌트도 T5 모델을 사용한다.
The QuestEval metric
Precision
요약문이 본문과 inconsistent한 지를 평가하기 위해서 precision을 평가한다. Precision을 평가할 때에는 요약문으로부터 QG를 통해 질문을 생성하여 생성한 질문을 본문과 함께 QA의 입력으로 넣어 출력된 답변과 실제 답변을 비교한다. 실제 답변의 경우 생성한 요약문에 있는 entity이기에, 본문에 실제로 해당 entity가 존재하는 지를 판단하며 precision을 평가한다.
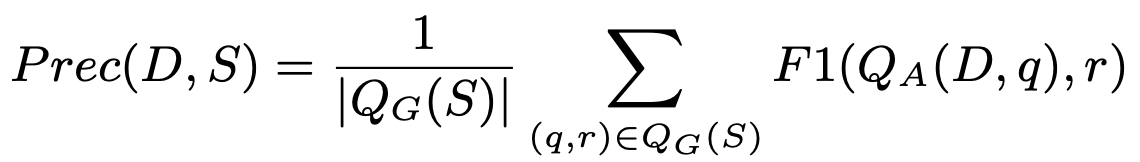
Recall
요약문이 본문의 중요한 정보만을 포함하고 있는 지를 판단하는 recall을 평가하기 위해 본문으로부터 생성한 질문을 요약문과 함께 QA의 입력으로 넣어 정답을 추출한다. 이 때 중요한 정보를 표시하기 위해서 Query Weighting을 사용한다. 사람이 생성한 요약문에 있는 entity들이 중요하다고 판단을 하여, 해당 entity들을 important라 레이블링하여 weight를 부과한다. 따라서 이러한 방법으로 entity들이 모델이 생성한 요약문에 있는 지의 여부를 파악하는 것으로 recall을 평가한다.
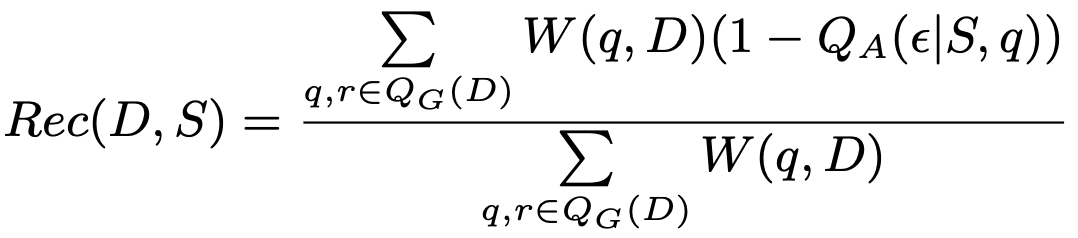
Experiment
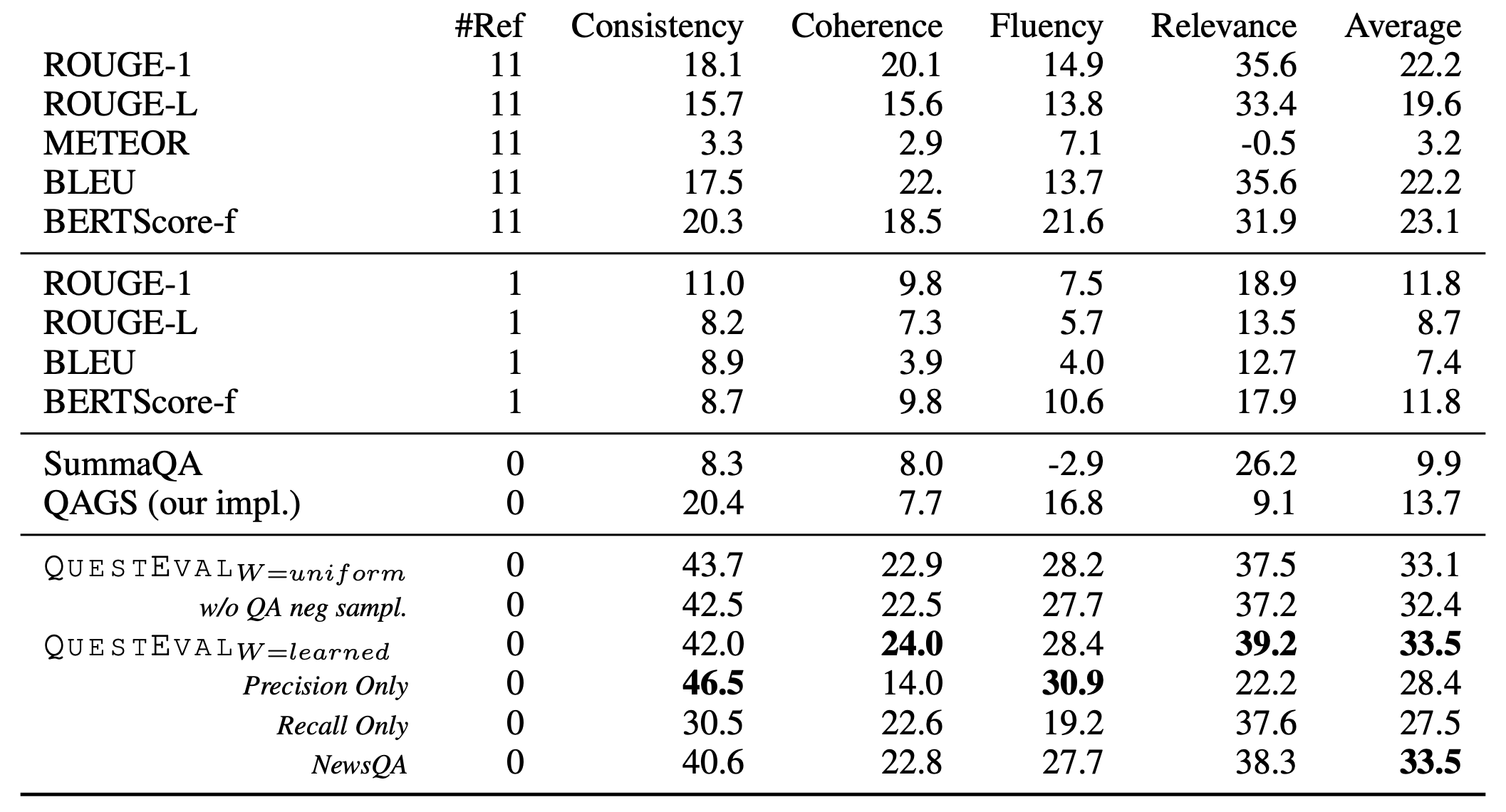
QuestEval을 평가하기 위해서 human-annotated 데이터 셋인 SummEval과의 상관관계를 계산하였다. 기존의 평가 지표들인 ROUGE, METEOR, BERTScore 등에 비해 월등하게 높은 상관관계를 보인다.
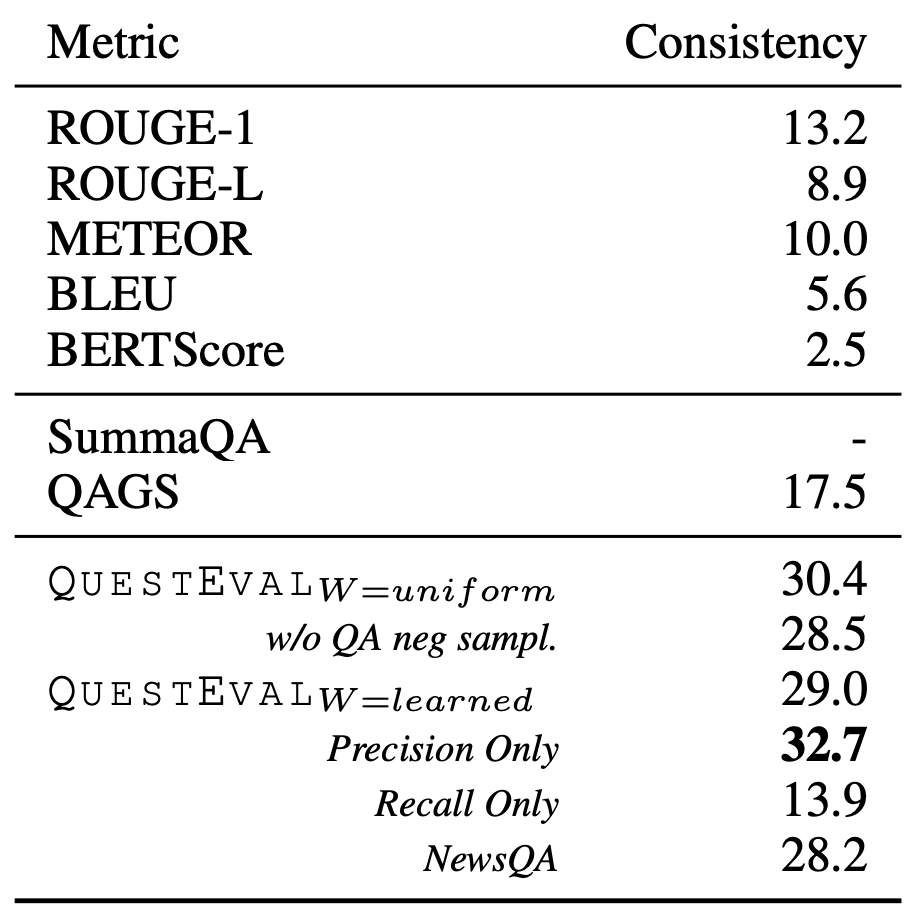
QAGS-XSum 데이터 셋을 사람이 평가한 consistency 점수와의 상관관계이다. QAGS-XSum 데이터 셋에서도 높은 상관관계를 보인다.

중요한 정보인데 답변이 된 것은 높은 양의 상관 계수를 보이고, 중요한 정보인데 답변이 되지 않은 것은 반대로 높은 음의 상관관계를 보인다. 반면 중요하지 않은데 답변이 된 것은 낮은 음의 상관관계를 보인다. 이를 통해 어떤 질문이 중요한 지 학습하는 해당 모델의 Query Weighter 방법이 가능하다는 것을 보여준다.
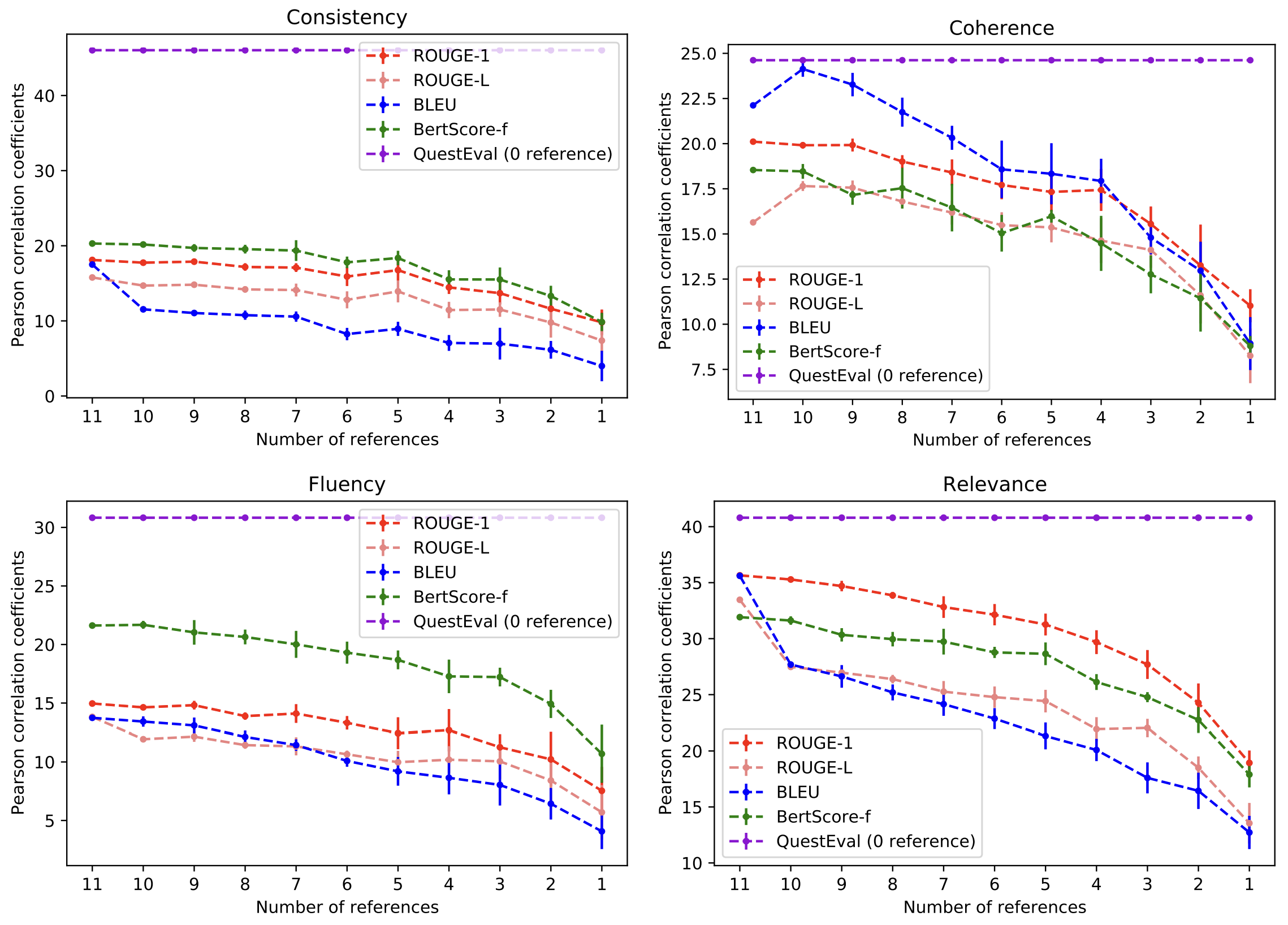
QuestEval의 경우 정답 요약문을 사용하지 않기 때문에 정답 요약문에 수에 따라 성능이 변화하는 기존의 평가 지표들과 달리 성능이 변화 없이 일정하다.
Comment
해당 논문에서 제안하는 QuestEval의 경우 consistency를 precision으로, relevance를 recall로 바라본다. 요약문에 있는 entity들이 실제로 본문에 있는 지 판단하면서 precision을 평가하고, 본문에 있는 중요한 entity들이 요약문에 있는 지 판단하면서 recall을 평가하는 것이 직관적이고 좋은 평가 접근인 것 같다. 다만 아쉬웠던 부분은 precision이나 recall을 계산할 때, 모든 named entity, noun을 추출하고, 추출된 단어들을 정답으로 삼아 beam search를 통해 질문을 생성하는데, 이러한 과정이 cost가 너무 커서 평가를 할 때, 다른 평가 지표들보다 시간이 너무 오래 걸린다는 점이다.